NOTICE: As of March 2025, the {gsm} package is no longer being maintained. It has been replaced by a series of modularized packages.
The contents of gsm have been split out among 4 packages as follows:
{gsm.core}: A package containing the analytics functionality and utility functions to run workflows.
{gsm.mapping}: A package that provides workflows to apply the necessary data transformation from raw/source datasets to appropriate domains.
{gsm.kri}: A package that provides workflows to generate metrics and functionality to visualize and report on these metrics.
{gsm.reporting}: A package that provides workflows to generate the reporting data model needed to generate reports.
The {gsm} package provides a standardized Risk Based Quality Monitoring (RBQM) framework for clinical trials that pairs a flexible data pipeline with robust reports like the one shown below.
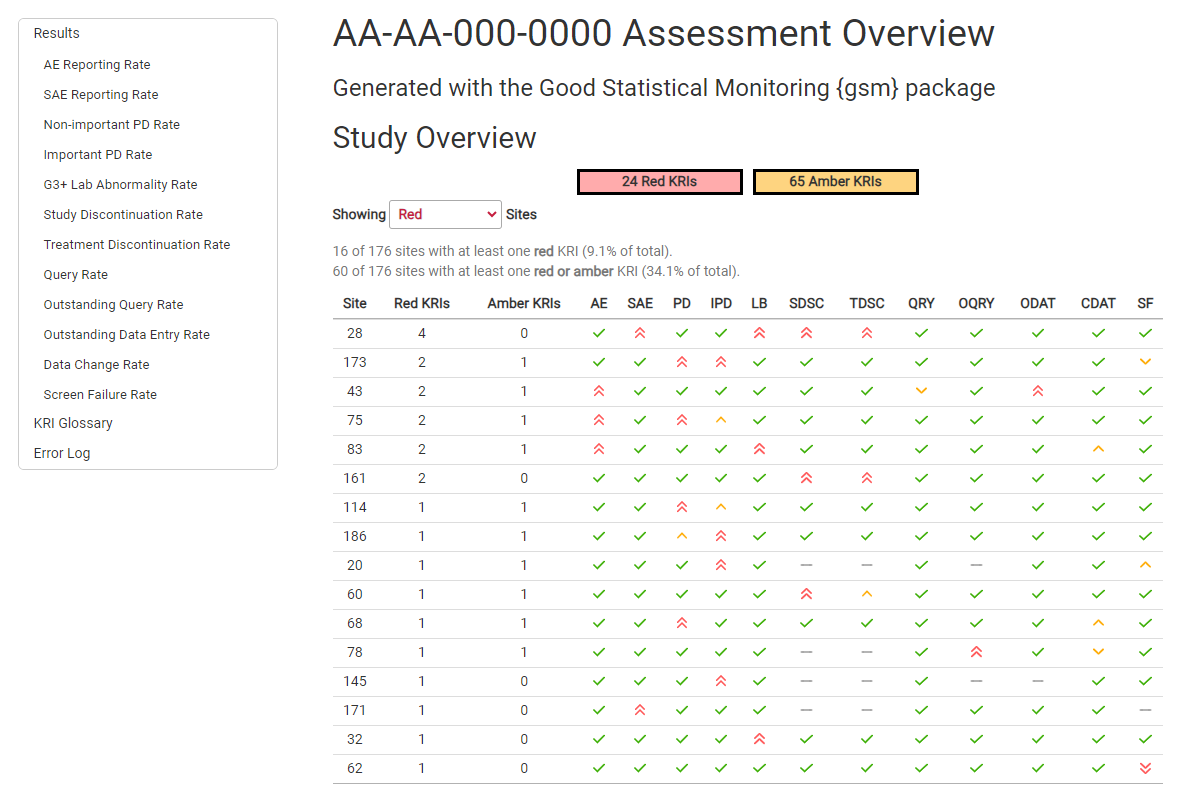
This README provides a high-level overview of {gsm}; see the package website for additional details.
Background
The {gsm} package performs risk assessments primarily focused on detecting differences in quality at the site-level. “High quality” is defined as the absence of errors that matter. We interpret this as focusing on detecting potential issues related to critical data or process across the major risk categories of safety, efficacy, disposition, treatment, and general quality, where each category consists of one or more risk assessment(s). Each risk assessment will analyze the data to flag sites with potential issues and provide a visualization to help the user understand the issue. Some relevant references are provided below.
Process Overview
The {gsm} package establishes a data pipeline for RBM using R. The package provides a framework that allows users to assess and visualize site-level risk in clinical trial data. The package currently provides assessments for the following domains:
- Adverse Event Reporting Rate
- Serious Adverse Event Reporting Rate
- Non-important Protocol Deviation Rate
- Important Protocol Deviation Rate
- Grade 3+ Lab Abnormality Rate
- Study Discontinuation Rate
- Treatment Discontinuation Rate
- Query Rate
- Outstanding Query Rate
- Outstanding Data Entry Rate
- Data Change Rate
- Screen Failure Rate
All {gsm} assessments use a standardized 6 step data pipeline:
-
Input_Rate - Converts
rawdata toinputdata. -
Transform - Converts
inputdata totransformeddata. -
Analyze - Converts
transformeddata toanalyzeddata. -
Threshold - Uses
analyzeddata to create one or more numericthresholds. -
Flag - Uses
analyzeddata and numericthresholdsto createflaggeddata. -
Summarize - Selects key columns from
flaggeddata to createsummarydata.
To learn more about {gsm}’s data pipeline, visit the Data Pipeline Vignette.
Reporting
Detailed RMarkdown/HTML reporting is built into gsm, and provides a detailed overview of all risk assessments for a given trial. For example, an AE risk assessment looks like this:
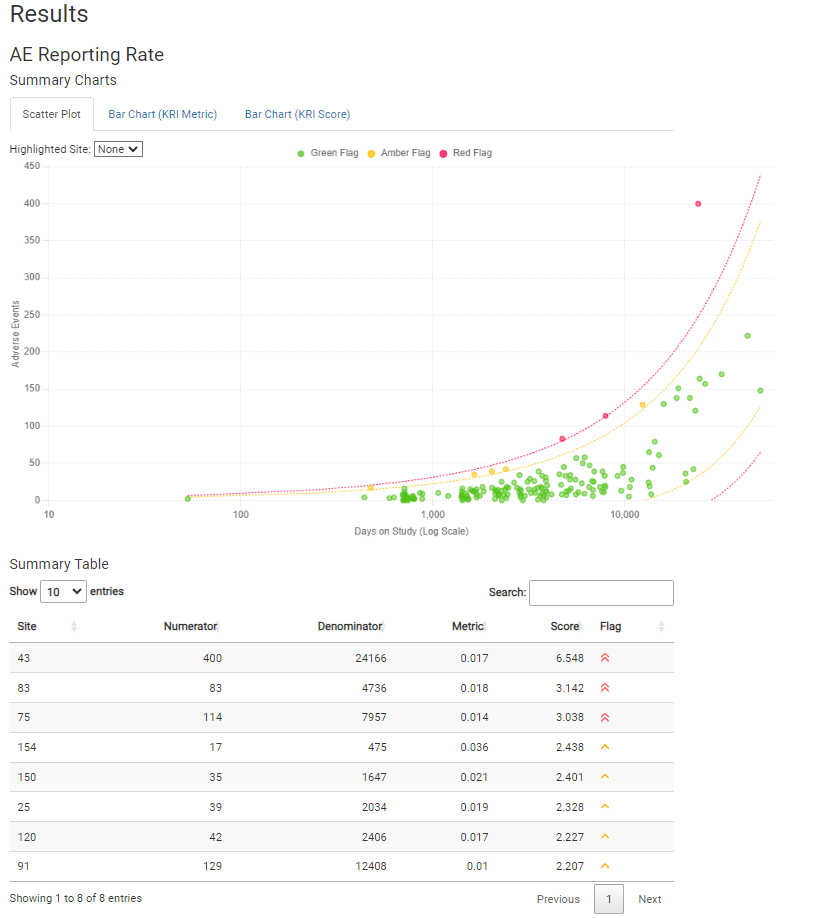
Full reports for a sample trial run with {clindata} are provided below:
Quality Control
Since {gsm} is designed for use in a GCP framework, we have conducted extensive quality control as part of our development process. In particular, we do the following:
- Qualification Workflow - All assessments have been Qualified as described in the Qualification Workflow Vignette. A Qualification Report Vignette is generated and attached to each release.
- Unit Tests - Unit tests are written for all core functions.
- Workflow Tests - Additional unit tests confirm that core workflows behave as expected.
- Contributor Guidelines - Detailed contributor guidelines including step-by-step processes for code development and releases are provided as a vignette.
- Data Model - Vignettes providing detailed descriptions of the data model.
- Code Examples - The Cookbook Vignette provides a series of simple examples, and all functions include examples as part of Roxygen documentation.
- Code Review - Code review is conducted using GitHub Pull Requests (PRs), and a log of all PRs is included in the Qualification Report Vignette.
- Function Documentation - Detailed documentation for each function is maintained with Roxygen.
- Package Checks - Standard package checks are run using GitHub Actions and must be passing before PRs are merged.
- Data Specifications - Machine-readable data specifications are maintained for all KRIs. Specifications are automatically added to relevant function documentation.
- Continuous Integration - Continuous integration is provided via GitHub Actions.
- Regression Testing - Extensive QC and testing is done before each release.
- Code Formatting - Code is formatted with {styler} before each release.
Additional detail, including links to functional documentation and vignettes, is available in the package website.